
今天给大家分享两个比较有用的浏览器行为与预期不一致的现象,这两个问题其实并不是什么难题,但在工作中发现不少人被难住了,在我的印象中至少有三位同事在群里问这样的问题,上周又有同事被此现象困住了,所以我觉得这应该是个共性问题,在这里分享给大家,希望对大家有帮助
现象一、点击按钮无法实现文件下载
前端同事反馈在浏览器里点击实现好的「下载商品图片」按钮却无法下载(预期应该下载 zip 文件)

但如果你在浏览器的地址栏里输入此下载地址却又能直接从浏览器里下载,这是为何?
我们可以打开调试工具「网络部分」,然后点击一下上面的「下载商品图片」,首先看一下网络请求是否正常。
1、 首先看请求头,可以看出状态码是 200,另外还有 content-disposition 与 Content-Type 这两个 response header
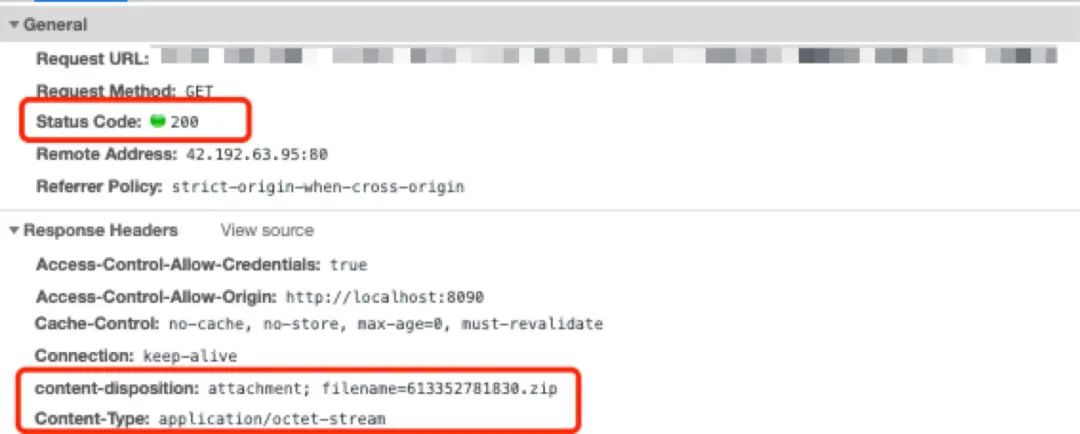
画外音:Content-Type: application/octet-stream 告诉客户端这是一个二进制文件,content-disposition 告诉客户端这是一个需要下载的附件并告诉浏览器该附件默认的文件名。
2、再看此请求的 response body,是否和步骤一的 application/octet-stream 相符:
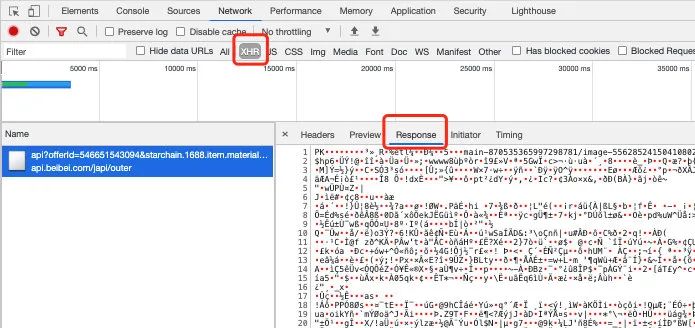
可以看到 response 就是一堆乱码,即文件的二进制流表现形式,所以从请求来看其实是没有问题的,文件是正常的返回的,但为啥文件却没有下载下来,下载下来的文件去哪里了呢,注意看上图的另一个红框 XHR ,它的全称是 XMLHttpRequest,是 ajax 请求的一种表现形式。
ajax 本身无法触发浏览器的下载功能, 它的 response 会交由 JavaScript 处理,使用 ajax 下载完成后,response 以字符串的形式存储在内存中,那使用 ajax 就没法下载了吗?不是的,我们看下浏览器为啥能下载
我们发现使用浏览器的 GET 请求(主要以 frame 加载, a 标签点击触发)或 POST请求(以 form 的形式存在)是可以下载文件的,因为这是浏览器的内置事件,下载的 response 会交由浏览器自己处理,浏览器如果识别到是二进制流数据则下载,如果识别到是可以打开的文件,如 xml, image 等则不会下载,会以预览的样式存在。
那么为啥 ajax 不能默认实现文件下载呢,这是浏览器的安全策略限制的,试想如果 ajax 可以下载文件,那就意味着 ajax 可以直接与磁盘交互,这会存在严重的安全隐患。
根据以上分析,要使用 ajax 下载文件我们也就有思路了,既然使用 a 标签(或 frame)的点击事件可以触发浏览器的内置下载行为,那我们在用 ajax 下载拿到 response 后,可以用 js 新建一个隐藏的 a 标签(标签的 href 指向文件的链接),执行它的 click 事件,这样就触发了浏览器的内置下载事件,就可以下载文件了,不过需要注意的事,创建的 a 标签中要添加一个 download 属性。 。
这个 download 属性有啥用呢,对于浏览器能打开的文件,例如 html,xml 等,如果你不加 download,点击 a 标签就不是下载了,而是打开。(注意 download 属性目前只被火狐和谷歌兼容)
使用 ajax 来执行下载文件的代码示例如下:
const filename = response.headers['content-disposition'].match(
/filename=(.*)/
)[1]
// 首先要创建一个 Blob 对象(表示不可变、原始数据的类文件对象)
const blob = new Blob([response.data], {type: 'application/zip'});
if (typeof window.navigator.msSaveBlob !== 'undefined') {
// 兼容IE,window.navigator.msSaveBlob:以本地方式保存文件
window.navigator.msSaveBlob(blob, decodeURI(filename))
} else {
let elink = document.createElement("a"); // 创建一个<a>标签
elink.style.display = "none"; // 隐藏标签
elink.href = window.URL.createObjectURL(blob); // 配置href,指向本地文件的内存地址
elink.download = filename;
elink.click();
URL.revokeObjectURL(elink.href); // 释放URL 对象
document.body.removeChild(elink); // 移除<a>标签
}现象二、在浏览器输入图片链接想预览,结果却变成了下载图片
这个问题其实经由上文分析,相信你不难猜出是咋回事,我们先抓包看一下:
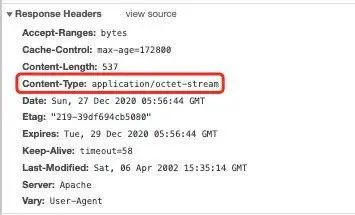
可以看到返回的 Content-Type 为 octet-stream,上文我们提到,它指任意类型的二进制流数据,一般下载文件返回的是这种类型,浏览器由于无法识别打开流数据,所以会下载,那为啥大多数图片在浏览器上是可以预览的呢,因为它返回的 Content-Type 是 image/png 或 image/jpeg 等浏览器可以直接识别打开的文件,这样就不会执行下载事件
总结
以上两个问题需要我们对浏览器的工作机制与 HTTP 协议有一定的了解,所以基础真的很重要啊,不然很可能你排查半天也无从下手,但如果你知道了这些原理,抓个包分析一下它们的 Content-Type,瞬间就豁然开朗了!另外对一些疑难杂症,了解 HTTP 协议与浏览器的工作机制也有助于帮助你快速定位解决问题。
比如上图的解决方案中我们通过 content-disposition 来获取文件的名称
const filename = response.headers['content-disposition'].match(
/filename=(.*)/
)[1]但在最开始发现这段代码有问题,打印日志发现 response.headers['content-disposition'] 居然为空,可是打开浏览器的 network 会发现, content-disposition 明明存在啊
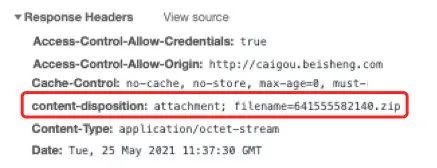
那为啥在 reponse 的 header 里拿不到 content-disposition 呢?
一查发现原来还是 HTTP 协议的问题
默认情况下,header 只有七种 simple response headers (简单响应首部)可以暴露给外部:
Cache-Control
Content-Language
Content-Length
Content-Type
Expires
Last-Modified
Pragma这里的暴露给外部,意思是让客户端(比如 Chrome)可以访问得到,既可以在 Network 里看到,也可以在代码里获取到他们的值。
而 content-disposition 不在其中,所以即使服务器在协议回包里加了该字段,如下
response.setHeader("content-disposition", "attachment; filename=" + filename);但因没“暴露”给外部,客户端就「看得到,吃不到」。
而响应首部 Access-Control-Expose-Headers 就是控制“暴露”的开关,它列出了哪些首部可以作为响应的一部分暴露给外部。
所以如果想要让客户端可以访问到其他的首部信息,服务器不仅要在 header 里加入该首部,还要将它们在 Access-Control-Expose-Headers 里面列出来,如下:
response.setHeader("Access-Control-Expose-Headers", "Content-Disposition");
response.setHeader("content-disposition", "attachment; filename=" + filename);这样的话 JS 的 response header 里就有 content-disposition 的值啦。
参考链接:
Access-Control-Expose-Headers: http://1il58.cn/AptUz
热文推荐:
————————————————
版权声明:本文为CSDN博主「公众号:码海」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_41385912/article/details/117268018
转载请注明:有爱前端 » 这个文件下载问题难住了我至少三位同事



